I've been working on my own implementation of SHA-1 hashing function. In the bigger picture I've put together a mostly working OAuth client using Groovy, and part of that is using HMAC-SHA1 to compute a secret value. Well I started by using the built in Java version but decided i would create my own... this is good exercise.
So first thing I did was write some unit tests. I needed SHA1 hashes to start with to make sure that my algorithm implementation works. The obvious choices are either sha1sum or openssl. I'm on a iMac running Leopard, and by default openssl is installed. I used that to compute some hash values. Unfortunately for me I spent a lot of time trying to get my algorithm working when it was already working. The problem was I computed the values wrong with openssl. I used the following:
echo "the quick fox jumps the brown dog" | openssl sha1
Which gave me a incorrect value. Why you ask? Well I didn't remember the -n flag and a newline character was being included in the string passed to openssl. Ooops! Well once I added the -n flag everything was fine and I now have a number of hash values to use in my tests.
Tuesday, October 28, 2008
Thursday, October 16, 2008
Eclipse, Tomcat, Sysdeo and the DevLoader (and a little Maven)
If you are developing a webapp in Eclipse there is a very good chance you are using Sysdeo. If you are not there is a very good chance you have not yet learned a proper way to debug a Java web application (or maybe you are using Jetty?). Sysdeo is really the only good open source, free Eclipse plugin for developing with Tomcat. It allows a simple way to debug your code in Eclipse while it runs in Tomkitty, a very nice thing.
Now the problem with the plugin out right is your project must be laid out like an exploded war... YUCK! This is because Sysdeo will be looking for the lib files under WEB-INF/lib and such. Often I've seen this lead to some truly horrible project organization, where jsp and Ant build files co-mingle in the same folder!?!
Most of us use a sane Ant or Maven project layout that is standardized across all our Java projects. If you want to continue doing so and leverage the benefits of Sysdeo then you will need the DevLoader installed.
If you haven't downloaded and installed the Sysdeo plugin do so now, I will wait ;)
Go here to get Sysdeo!
Ok once installed you should see 3 icons under the Eclipse menu bar that look very familiar (they are Tomcats!). The first icon starts Tomcat, the second stops it and the third restarts. Now open the Eclipse preferences menu. You should see the "Tomcat" entry. Open it and configure the plugin based on your Tomcat installation. You will want the "Context Declaration mode" to be "context" in my experience. It just makes things a lot cleaner if you use Tomcat for other projects/apps, where they each have individual files rather being crammed in server.xml. That should be about all you need to know. Oh the sub-menu 'Source path' is for adding the source files used in debugging, so make sure your project is in there if you want to be able to see the files while debugging.
Next up the DevLoader. It came with the Sysdeo plugin when you download it! You should find a zip file in the the Sysdeo zip aptly named Devloader.zip. Unzip it. It will create an org folder, within lies some classes. Jar this sucker up:
This should create a jar for the DevLoader. Now throw this in your Tomcat instance's lib folder.
Great now you have almost everything you need to get started. Lets go over an example of a Maven project being used.
In Maven the webapp files go in src/main/webapp by convention, and sources go in src/main/java, and the resource files (xml, properties) go into src/main/resources. For your Maven project you would right click the project and select properties. You should now notice a 'Tomcat' entry in the config options. Select this.
Enable the "Is a Tomcat Project" checkbox. For the 'context name' use whatever sane value you prefer. Near the bottom area you will want to enter 'src/main/webapp' for the app root. This is where most jsp, html, javascrpt, css and whatnot will be. You will be able to update these and see the result. Now the last thing we need to do is activate the devloader. Here is a picture of what that looks like:
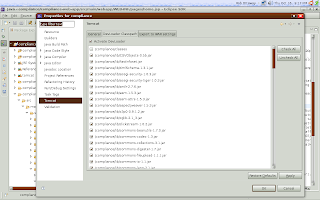
So really all you do is add the jar files needed. Thats it. Now save. If you are not going to create a context file yourself, and you enabled 'can update context definition' in the projects tomcat properties you can right click the project and select "tomcat project > update context definition". This will automatically create the proper context file for Tomcat, so that it uses the DevLoader and your project. You almost certainly will want to do this. Note you can further alter the automatically created context file afterwards.
Now the problem with the plugin out right is your project must be laid out like an exploded war... YUCK! This is because Sysdeo will be looking for the lib files under WEB-INF/lib and such. Often I've seen this lead to some truly horrible project organization, where jsp and Ant build files co-mingle in the same folder!?!
Most of us use a sane Ant or Maven project layout that is standardized across all our Java projects. If you want to continue doing so and leverage the benefits of Sysdeo then you will need the DevLoader installed.
If you haven't downloaded and installed the Sysdeo plugin do so now, I will wait ;)
Go here to get Sysdeo!
Ok once installed you should see 3 icons under the Eclipse menu bar that look very familiar (they are Tomcats!). The first icon starts Tomcat, the second stops it and the third restarts. Now open the Eclipse preferences menu. You should see the "Tomcat" entry. Open it and configure the plugin based on your Tomcat installation. You will want the "Context Declaration mode" to be "context" in my experience. It just makes things a lot cleaner if you use Tomcat for other projects/apps, where they each have individual files rather being crammed in server.xml. That should be about all you need to know. Oh the sub-menu 'Source path' is for adding the source files used in debugging, so make sure your project is in there if you want to be able to see the files while debugging.
Next up the DevLoader. It came with the Sysdeo plugin when you download it! You should find a zip file in the the Sysdeo zip aptly named Devloader.zip. Unzip it. It will create an org folder, within lies some classes. Jar this sucker up:
jar cf devloader.jar org/
This should create a jar for the DevLoader. Now throw this in your Tomcat instance's lib folder.
Great now you have almost everything you need to get started. Lets go over an example of a Maven project being used.
In Maven the webapp files go in src/main/webapp by convention, and sources go in src/main/java, and the resource files (xml, properties) go into src/main/resources. For your Maven project you would right click the project and select properties. You should now notice a 'Tomcat' entry in the config options. Select this.
Enable the "Is a Tomcat Project" checkbox. For the 'context name' use whatever sane value you prefer. Near the bottom area you will want to enter 'src/main/webapp' for the app root. This is where most jsp, html, javascrpt, css and whatnot will be. You will be able to update these and see the result. Now the last thing we need to do is activate the devloader. Here is a picture of what that looks like:

So really all you do is add the jar files needed. Thats it. Now save. If you are not going to create a context file yourself, and you enabled 'can update context definition' in the projects tomcat properties you can right click the project and select "tomcat project > update context definition". This will automatically create the proper context file for Tomcat, so that it uses the DevLoader and your project. You almost certainly will want to do this. Note you can further alter the automatically created context file afterwards.
Monday, October 13, 2008
Sorting using Haskell
Last Friday night I had some fun writing sorts in Haskell. Yes thats right I spent my Friday night working on some rudimentary algorithms in an obscure computer language. Lets just say I'm in to that kinda thing. Oh well it beats being addicted to cough syrup.
So Haskell is fun. There I said it. It is the kinda language which lends much balance to ones style, is one is a imperitive/OO language flunky. The ideas in Haskell seem bizarre at first but become beautiful as they sink in. Sink they do, lets look at the first sort, the almighty BUBBLE SORT
I imagine that looks weird. Well it should, if you are unaccustomed to Haskell. The syntax is much different than any OO language. I've had people tell me Python is too weird looking. Well this would just frighten those types of people silly. Lets talk about this code
The first thing to point out is the signature. In leyman's terms this says "take a list of something and return a list of something". The last [t] is going to be what is returned. The '(Ord t)' says that t must be of the typeclass 'Ord' as in 'Ordinality' which is related to being able to compare values. Don't worry too much about that for now, just know it allows us to do things like '>', '<', '==' and so on.
The rest is easy to explain. The bubbleSort function will loop x times, x being the length of the list to be sorted. For a list of 10 elements we loop 10 times. Each time we loop we call bubble. See the loop function takes a number (a) and a function (t -> t), and finally a value (t). What we end up doing here is calling loop again with the number decremented by one. We call bubble on the value, then passing the result right back into bubble IF the number is greater than 0.
This bubble function will go through the list comparing each pair elements, starting with the first and second, and swapping them if the first is greater than the second. This causes the largest value to 'bubble up' to the top of the list.
So Haskell is fun. There I said it. It is the kinda language which lends much balance to ones style, is one is a imperitive/OO language flunky. The ideas in Haskell seem bizarre at first but become beautiful as they sink in. Sink they do, lets look at the first sort, the almighty BUBBLE SORT
-- Implementation of a bubble sort in Haskell
bubbleSort :: (Ord t) => [t] -> [t] -- signature
bubbleSort a = loop (length a) bubble a
bubble :: (Ord t) => [t] -> [t]
bubble (a:b:c) | a < b = a : bubble (b:c)
| otherwise = b : bubble (a:c)
bubble (a:[]) = [a]
bubble [] = []
loop :: (Num a, Ord a) => a -> (t -> t) -> t -> t
loop num f x | num > 0 = loop (num-1) f x'
| otherwise = x
where x' = f x
I imagine that looks weird. Well it should, if you are unaccustomed to Haskell. The syntax is much different than any OO language. I've had people tell me Python is too weird looking. Well this would just frighten those types of people silly. Lets talk about this code
The first thing to point out is the signature. In leyman's terms this says "take a list of something and return a list of something". The last [t] is going to be what is returned. The '(Ord t)' says that t must be of the typeclass 'Ord' as in 'Ordinality' which is related to being able to compare values. Don't worry too much about that for now, just know it allows us to do things like '>', '<', '==' and so on.
The rest is easy to explain. The bubbleSort function will loop x times, x being the length of the list to be sorted. For a list of 10 elements we loop 10 times. Each time we loop we call bubble. See the loop function takes a number (a) and a function (t -> t), and finally a value (t). What we end up doing here is calling loop again with the number decremented by one. We call bubble on the value, then passing the result right back into bubble IF the number is greater than 0.
This bubble function will go through the list comparing each pair elements, starting with the first and second, and swapping them if the first is greater than the second. This causes the largest value to 'bubble up' to the top of the list.
Tuesday, September 2, 2008
Languages
This is a quick post about some great learning options for a pair of functional languages. You may be interested in seeing a functional approach to computer languages. I recommend Haskell or Erlang. For Haskell I recommend the book "Real World Haskell". You can read it online; it will also be published by O'Reilly. For Erlang check out "Getting Started with Erlang", also free. Once you've wet your feet with Erlang you can check read the manual whenever you need a refresher.
Sunday, August 24, 2008
Hacking Eclipse plugin configurations

Reading Neal Ford's generally excellent book The Productive Programmer, I experimented with his multiple plugin configuration hack. In short, creating multiple plugin configurations in a single eclipse install allows for a team to keep their plugin configurations in version control, so everyone has exactly the same configurations as anyone else on the team. No more "works on my machine but not on yours" weirdness. You can even manage them on a project-by-project basis, which is good.
But there are two aspects of working with multiple plugin configurations that are strange: specifically, creating and deleting them. In order to create an additional plugin configuration, you have to:
From there, you can go to Help -> Software Updates -> Manage Configuration and add your configuration location(s). Then it's a simple matter of installing your plugins to the config locations desired. You can then enable and disable multiple plugins as a group, switch between versions, etc. It's very handy.
But I'd mentioned that there were two strange things about the process. Creating additional configuration locations was one, deleting them was the second. Just as Eclipse gives you no love in creating them, it makes it even harder to get rid of them.
Let's say, for example, that you've added your new location as an extension not to the top-level list, but as an extension to an extension. (Yes, you can do this.) But let's also say that's not what you wanted. Well, you can disable your extension-within-an-extension, but you can't get Eclipse to ignore its existence entirely. If you then try to add it to the top level, Eclipse won't let you, complaining that you've already added it elsewhere. Arg.
Well, there's a way around that, too (but Ford doesn't mention it). Under ${ECLIPSE_HOME}/configuration/org.eclipse.update there's a file called platform.xml. Up at the top there are "site" nodes, and one of those will be your offender. Delete the bad guy and restart Eclipse. Now you can place your configuration elsewhere. (Or, you can just change the path in the node).
Anyway, as noted, there's a lot to gain by using multiple plugin configuarations, once you get around Eclipse's strange reluctance to make it intuitive. Happy hacking!
But there are two aspects of working with multiple plugin configurations that are strange: specifically, creating and deleting them. In order to create an additional plugin configuration, you have to:
- Create a folder to hold the configuration. It must be named "eclipse" and it must not be in Eclipse's directory structure.
- Within your "eclipse" folder, you have to make an empty file called .eclipseextension, and two empty folders, features and plugins.
From there, you can go to Help -> Software Updates -> Manage Configuration and add your configuration location(s). Then it's a simple matter of installing your plugins to the config locations desired. You can then enable and disable multiple plugins as a group, switch between versions, etc. It's very handy.
But I'd mentioned that there were two strange things about the process. Creating additional configuration locations was one, deleting them was the second. Just as Eclipse gives you no love in creating them, it makes it even harder to get rid of them.
Let's say, for example, that you've added your new location as an extension not to the top-level list, but as an extension to an extension. (Yes, you can do this.) But let's also say that's not what you wanted. Well, you can disable your extension-within-an-extension, but you can't get Eclipse to ignore its existence entirely. If you then try to add it to the top level, Eclipse won't let you, complaining that you've already added it elsewhere. Arg.
Well, there's a way around that, too (but Ford doesn't mention it). Under ${ECLIPSE_HOME}/configuration/org.eclipse.update there's a file called platform.xml. Up at the top there are "site" nodes, and one of those will be your offender. Delete the bad guy and restart Eclipse. Now you can place your configuration elsewhere. (Or, you can just change the path in the node).
Anyway, as noted, there's a lot to gain by using multiple plugin configuarations, once you get around Eclipse's strange reluctance to make it intuitive. Happy hacking!
Tuesday, August 19, 2008
Windoze tools - Infra Recorder
If you somehow find yourself on a Windows machine and need to burn an image (iso) to a cd or dvd then I recommend Infra Recorder. I've used it a year or two ago, but found it again today and have to say it is looking and working good.
Mojave Experiment - an open insult to Windows users
If you haven't heard of Microsoft's newest advertising venture called Mojave Experiment let me fill you in. It is an 'experiment' (their words not mine) in which Windows XP users are asked to test out a cutting edge new M$ OS. Well it turns out this is just Vista. The punchline is users loveVista, just give it a chance all you mean naysayers. Well I think users don't like Vista and for good reasons. That is why it has not caught fire like M$ thinks it should have. Well I feel safe saying the execs up in Redwood must have lost their shit, having drunk their own Kool-Aid far too long. For a thorough examination check out this article. Peace!
Monday, August 4, 2008
Installing CouchDB on Gentoo
So I recently installed CouchDB on Gentoo at work and I figured for others sake I would post clear concise directions.
Portage setup
You are going to want a Portage overlay in which to put your own ebuild scripts. Having such a place will keep separation between the core Gentoo ebuilds and stuff you dabble with. Lets start with adding your Portage overlay: 'sudo mkdir -p /usr/local/portage'. This is where we are going to put your custom ebuilds. If you are interested, look in '/usr/portage'. Here you will see a lot of ebuilds that come via Gentoo's network.
To notify Gentoo (more specifically Portage) of this new overlay you will want to add the following line into the '/etc/make.conf' file:
To make Portage aware of this new category I add the line 'ottaway' to the '/etc/portage/categories' file.
Getting CouchDB
You will need to get the ebuild script for CouchDB. It is found as an attachment on this page. I used the following to download the script:
Next up you are going to have to tell Gentoo that you are ok with certain development ebuilds being installed. I did this by adding the following lines to the '/usr/portage/package.keywords' file:
Next up I was ready to install the whole thing. You can do so using:
is the name you gave your category you created earlier. Once this starts moving you can sit back and relax. When it finishes you can use "sudo -u couchdb couchdb" to get things started. When you see the "time to relax" pop onto the screen go ahead and hit your instance @ http://<yourdomain>:5984/_utils/index.html, where <yourdomain> is the network name of the machine CouchDB is running on.
Portage setup
You are going to want a Portage overlay in which to put your own ebuild scripts. Having such a place will keep separation between the core Gentoo ebuilds and stuff you dabble with. Lets start with adding your Portage overlay: 'sudo mkdir -p /usr/local/portage'. This is where we are going to put your custom ebuilds. If you are interested, look in '/usr/portage'. Here you will see a lot of ebuilds that come via Gentoo's network.
To notify Gentoo (more specifically Portage) of this new overlay you will want to add the following line into the '/etc/make.conf' file:
PORTDIR_OVERLAY="/usr/local/portage"Next up we need to have a category. Categories separate ebuilds by function and or purpose. For instance the web Server Apache is found in the 'www-servers' category. You can maybe find it @ '/usr/portage/www-servers' on your machine. You can pick any category name you like for this exercise. I'm going to be using 'ottaway'. For the category create a folder in '/usr/local/portage', in my case I do 'sudo mkdir /usr/local/portage/ottaway'. Substitute 'ottaway' for the name of your category.
To make Portage aware of this new category I add the line 'ottaway' to the '/etc/portage/categories' file.
Getting CouchDB
You will need to get the ebuild script for CouchDB. It is found as an attachment on this page. I used the following to download the script:
curl https://bugs.gentoo.org/attachment.cgi?id=159315 > couchdb-0.8.0.ebuildYou could pretty easily use wget also. I put this in my Portage overlay in my custom category @ '/usr/local/portage/ottaway', you must do the same for your category.
Next up you are going to have to tell Gentoo that you are ok with certain development ebuilds being installed. I did this by adding the following lines to the '/usr/portage/package.keywords' file:
# couchdb stuffYou can put those lines anywhere in the file. If you used a category name other than 'ottaway' change the value in the last line of the example above.
dev-lang/erlang
dev-util/svn2cl
dev-lang/spidermonkey
ottaway/couchdb ~x86
Next up I was ready to install the whole thing. You can do so using:
sudo emerge =Where <yourcategory><yourcategory>/couchdb-0.8.0
Friday, August 1, 2008
Hurting the CouchDB
The needs of many
These days companies have a lot of records floating around. At the last eCommerce company I worked for there where many millions of records floating around our Oracle database. I feel as you get into that sort of situation two things happen: your have very small lines of inter connectivity between the records, as they are spread across all those tables, and secondly you find yourself yielding more and more to the whims of the database system. I've started toying with CouchDB (which is itself only a toy at this point).
I've thrown in over 12k documents to CouchDB so far. I've taken my companies whole product catalog and serialized it from simple XML to even simpler JSON. Each document was about roughly 300kb. Each document contains things like product data, many records which make up the production history of the product, and just about anything related to a product. Performance is good, with 12k docs in the system I notice no difference in request times from 10 documents. It appears that CouchDB doesn't care about how many documents you are storing, it simply is relying on the underlying system to provide the space on disk.
It Handles lots of documents
Thats great and all but how big can these documents get? I'm looking to move from relational to document based which means for a customer document you have order history, purchased items and many other things. Rather than have the summation of a customer, the most important business entity, spread out all over the DB system why not put their 'story' into one document? Yes some of this data could end up being redundant, but that's the point. Don't worry too much about the small stuff, worry about the stuff that really hurts later down the road like being able to provide a correct SQL statement to put together a Customer model! At my big eCommerce company that was damn near impossible, with many people having separate interpretations! Ouch! A document can be self describing, a big plus when the data model gets complex.
To keep perspective going forward I will use the metric of WAP (or "War and Peace"). This is an epic document written by the Russian author Leo Tolstoy. Here it is over at Wikipedia, yes it is huge. I feel this makes a good metric because it is so big. YOU will never write your own "War and Peace". In the real world this book is a freak of nature, say the Andre the Giant of books. I downloaded a free version off the net, and the size was 3.2 MB, keep this number in mind.
So we need to determine if documents could get to these really large sizes without worries. I mean we can think up a reasonable size to which now document will ever grow. I asked myself "Could my companies product records increase in size by 100x and still CouchDB serves em up?". At this size would the client even be able to parse and hold the object in memory? Does that matter? Can I use views (in the CouchDB sense) to pare down a document to just the parts the client needs?
Well I started by simply increasing the size of a larger product document by 3600x. Yeah I'm shooting for the moon here. The documents size was ~46Mb, or ~15 WAP. Well on POST of the document to CouchDB things looked good but after a minute CouchDB crashed:
eheap_alloc: Cannot allocate 729810240 bytes of memory (of type "heap").
Aborted
I'm sorry CouchDB... not! I am running the db on a virtual slice that doesn't have too much memory available. Still it doesn't have to deal with multiple clients making requests. So maybe there needs to be a feature where documents of certain size are handled differently due to their size. I'm guessing that currently the whole document is parsed into memory, probably not a great idea for large documents, but good for performance overall.
Next I tried halving the document's size, from 3600x to 1800x, with a relative size of 7 WAP. Again this blew up with problems allocating memory. Ok next up 900x... hey it worked! Using my unoptimized vanilla install on a Gentoo slice I can upload a document that is 3.5-4 WAP in size. That is a lot of reading :) I now ask myself "so at that size what can you expect from clients?".
Clients the other white meat
Right off, no current browser can handle this 900x document. Just too freaking big. Requesting such a doc wouldn't make much sense in most cases. Really, what kind of web pages need all that data at once? Take into consideration that the browser will have to pass it onto a Javascript engine and allow it to parse the content. Parsing always takes time. Depending on the Javascript engine being used this time could range from slow to really slow.
If we could get just the pieces that are needed from the document a client would be much better off. Think of lazy fetching in SQLAlchemy or Hibernate, where the ORM layer doesn't load everything at once, but can get things when asked for. Well I think that the CouchDB view feature will allow you to cut down the size of a document, maybe for a customer document you get just the order history, or contact info. Then you update that doc and merge it back into the document.
I put a 200x document into the DB. Using the metric this is about 0.7 WAP, still very large. Fire Fox 3 loaded the structure in 32-33 seconds in Futon. At this size the request took 1-2 seconds when using cUrl via the command line to request the object. Using this CouchDB Python library it took 4-5 seconds to get the 200x doc from CouchDb. Not bad if you really needed to parse that much data. To again put things in perspective this is 0.7 War and Peace books. Thats pretty big.
So, are there even applications for document that get so big? I can think of a certain historical report that really could use all this info to generate a complete history of who changed what and when, how things changed (more in a minute), give the all the data surrounding a product, who has what access and more.
On keeping track
Now I haven't spoke of it yet but there is also a feature built into CouchDB where a document's changes can be tracked. Basically you can review the changes over time. I'm not going to do any testing of performance in history, I'll save that for later. I just wanted to point out that this feature is very cool and useful.
What I need to do
I need to actually build and maintain something using CouchDB. I've looked and listened for stories on using CouchDB and have found little. I can relate though to using Mark Logic, a XML database which is therefore document based, and having good results. The site SafariU (maybe gone by now) used mostly XQuery to manage documents that contained things such as user info like subscriptions. It worked pretty good. You did end up replacing SQL for XQuery, but XQuery was a much better tool I feel than SQL was. Anyway, I will be toying around and will post more on CouchDB if and when I find something more out.
These days companies have a lot of records floating around. At the last eCommerce company I worked for there where many millions of records floating around our Oracle database. I feel as you get into that sort of situation two things happen: your have very small lines of inter connectivity between the records, as they are spread across all those tables, and secondly you find yourself yielding more and more to the whims of the database system. I've started toying with CouchDB (which is itself only a toy at this point).
I've thrown in over 12k documents to CouchDB so far. I've taken my companies whole product catalog and serialized it from simple XML to even simpler JSON. Each document was about roughly 300kb. Each document contains things like product data, many records which make up the production history of the product, and just about anything related to a product. Performance is good, with 12k docs in the system I notice no difference in request times from 10 documents. It appears that CouchDB doesn't care about how many documents you are storing, it simply is relying on the underlying system to provide the space on disk.
It Handles lots of documents
Thats great and all but how big can these documents get? I'm looking to move from relational to document based which means for a customer document you have order history, purchased items and many other things. Rather than have the summation of a customer, the most important business entity, spread out all over the DB system why not put their 'story' into one document? Yes some of this data could end up being redundant, but that's the point. Don't worry too much about the small stuff, worry about the stuff that really hurts later down the road like being able to provide a correct SQL statement to put together a Customer model! At my big eCommerce company that was damn near impossible, with many people having separate interpretations! Ouch! A document can be self describing, a big plus when the data model gets complex.
To keep perspective going forward I will use the metric of WAP (or "War and Peace"). This is an epic document written by the Russian author Leo Tolstoy. Here it is over at Wikipedia, yes it is huge. I feel this makes a good metric because it is so big. YOU will never write your own "War and Peace". In the real world this book is a freak of nature, say the Andre the Giant of books. I downloaded a free version off the net, and the size was 3.2 MB, keep this number in mind.
So we need to determine if documents could get to these really large sizes without worries. I mean we can think up a reasonable size to which now document will ever grow. I asked myself "Could my companies product records increase in size by 100x and still CouchDB serves em up?". At this size would the client even be able to parse and hold the object in memory? Does that matter? Can I use views (in the CouchDB sense) to pare down a document to just the parts the client needs?
Well I started by simply increasing the size of a larger product document by 3600x. Yeah I'm shooting for the moon here. The documents size was ~46Mb, or ~15 WAP. Well on POST of the document to CouchDB things looked good but after a minute CouchDB crashed:
eheap_alloc: Cannot allocate 729810240 bytes of memory (of type "heap").
Aborted
I'm sorry CouchDB... not! I am running the db on a virtual slice that doesn't have too much memory available. Still it doesn't have to deal with multiple clients making requests. So maybe there needs to be a feature where documents of certain size are handled differently due to their size. I'm guessing that currently the whole document is parsed into memory, probably not a great idea for large documents, but good for performance overall.
Next I tried halving the document's size, from 3600x to 1800x, with a relative size of 7 WAP. Again this blew up with problems allocating memory. Ok next up 900x... hey it worked! Using my unoptimized vanilla install on a Gentoo slice I can upload a document that is 3.5-4 WAP in size. That is a lot of reading :) I now ask myself "so at that size what can you expect from clients?".
Clients the other white meat
Right off, no current browser can handle this 900x document. Just too freaking big. Requesting such a doc wouldn't make much sense in most cases. Really, what kind of web pages need all that data at once? Take into consideration that the browser will have to pass it onto a Javascript engine and allow it to parse the content. Parsing always takes time. Depending on the Javascript engine being used this time could range from slow to really slow.
If we could get just the pieces that are needed from the document a client would be much better off. Think of lazy fetching in SQLAlchemy or Hibernate, where the ORM layer doesn't load everything at once, but can get things when asked for. Well I think that the CouchDB view feature will allow you to cut down the size of a document, maybe for a customer document you get just the order history, or contact info. Then you update that doc and merge it back into the document.
I put a 200x document into the DB. Using the metric this is about 0.7 WAP, still very large. Fire Fox 3 loaded the structure in 32-33 seconds in Futon. At this size the request took 1-2 seconds when using cUrl via the command line to request the object. Using this CouchDB Python library it took 4-5 seconds to get the 200x doc from CouchDb. Not bad if you really needed to parse that much data. To again put things in perspective this is 0.7 War and Peace books. Thats pretty big.
So, are there even applications for document that get so big? I can think of a certain historical report that really could use all this info to generate a complete history of who changed what and when, how things changed (more in a minute), give the all the data surrounding a product, who has what access and more.
On keeping track
Now I haven't spoke of it yet but there is also a feature built into CouchDB where a document's changes can be tracked. Basically you can review the changes over time. I'm not going to do any testing of performance in history, I'll save that for later. I just wanted to point out that this feature is very cool and useful.
What I need to do
I need to actually build and maintain something using CouchDB. I've looked and listened for stories on using CouchDB and have found little. I can relate though to using Mark Logic, a XML database which is therefore document based, and having good results. The site SafariU (maybe gone by now) used mostly XQuery to manage documents that contained things such as user info like subscriptions. It worked pretty good. You did end up replacing SQL for XQuery, but XQuery was a much better tool I feel than SQL was. Anyway, I will be toying around and will post more on CouchDB if and when I find something more out.
Wednesday, July 30, 2008
couchdb is the popeyes chicken of cool new ideas...
... by that I mean it is f**king awsome. I mean it give it a look. I love the fact that it uses Spidermonkey so that I can define map-reduce views of large collections of data. I love that it uses HTTP as the protocol for operating on the data. I like the idea of documents being the central worry of my persistance layer, being that almost every web app I have every written cares about documents, not bean counting which relational databases have been so suited to. My hat is off to the commiters on this project. It is truely something that I feels is needed for us common software commandos. I'm a bit worried about modelling real world entities such as products, people and such using a old fashion relational db. I understand there are cases where such a system just works. But I would like a chance to further explore a more restful approach to data models.
Friday, May 2, 2008
Perl how you offend me (sometimes)
I've been fishing around with Perl over the last month. Got a big legacy PIM application to deal with. Oh my! This app is running on Apache and mod_perl. These are some old school technologies. I'm sure there are lots of burnt out mod_perl programmers out there who are much more qualified to work on this shit. I bet they don't bother to put this stuff on their resume, not as long as they have money in the bank, and/or a roof over their head. Scratch that maybe even without those... having gotten acquainted to this stuff homelessness may be preferable. Sad sad. I don't dislike Perl. It has it's charms and especially evokes finer feelings of classic-ness. It's the language that helped build the net into what it is... a giant commercial cesspool slash platform for extremists of the opinionated sort and trans-generational masturbatory aid. Wow what a legacy.
So there it is. Why should I respect something merely because it's author has a rad mustache and sweet Hawaiian shirt collection? Perl in my very humble opinion is too prickly for the newer generation (which I kinda am in). It has nice features: hashes real nice.. lists real nice... CPAN amazing... come on though, for each thing it does right it does numerous things wrong or in poor taste. Arguments to functions blah, references why are you so lousy looking and overly complicated? And strict, dumbest vestigial lousy feature ever. Classes are disgustingly complicated to pick up... bless?!? Lots of sharp edges. Dispite all this Perl has lit the way for many. I've met people that are now programmers because they found Perl. Lets face it though, languages have severely changed since Perl's founding. Most people who program Perl have changed too.
I recently read Perl is not dead, sure I agree, it is just legacy. Cobol and Fortran are not REALLY dead either. But you couldn't lure me into doing either, not with a six pack of Micky's and a Snickers bar. There are few things golden left for those of great Perl skills to be looked forward to. All the cool kids have moved onto Python and Ruby, even Java I may argue. These people of skill would have little difficulty picking up another language. The true hacker/scholar/intellectual will thrive on a new language, enjoying the diversity of human creation. They also should have little holding them back from trying something new. I wager those who make the effort will quickly make the transition to the new language and never look back. This may include a change of job.
To wrap it up Perl is like the obnoxious slob at a party to which you want to avoid. Difficult to deal, disheveled and unkempt, but also sometimes fun. If you are learning to program, or have done a bit of programming learn Python (or maybe Ruby). Stay away from Perl. Also don't go near PHP, please!
So there it is. Why should I respect something merely because it's author has a rad mustache and sweet Hawaiian shirt collection? Perl in my very humble opinion is too prickly for the newer generation (which I kinda am in). It has nice features: hashes real nice.. lists real nice... CPAN amazing... come on though, for each thing it does right it does numerous things wrong or in poor taste. Arguments to functions blah, references why are you so lousy looking and overly complicated? And strict, dumbest vestigial lousy feature ever. Classes are disgustingly complicated to pick up... bless?!? Lots of sharp edges. Dispite all this Perl has lit the way for many. I've met people that are now programmers because they found Perl. Lets face it though, languages have severely changed since Perl's founding. Most people who program Perl have changed too.
I recently read Perl is not dead, sure I agree, it is just legacy. Cobol and Fortran are not REALLY dead either. But you couldn't lure me into doing either, not with a six pack of Micky's and a Snickers bar. There are few things golden left for those of great Perl skills to be looked forward to. All the cool kids have moved onto Python and Ruby, even Java I may argue. These people of skill would have little difficulty picking up another language. The true hacker/scholar/intellectual will thrive on a new language, enjoying the diversity of human creation. They also should have little holding them back from trying something new. I wager those who make the effort will quickly make the transition to the new language and never look back. This may include a change of job.
To wrap it up Perl is like the obnoxious slob at a party to which you want to avoid. Difficult to deal, disheveled and unkempt, but also sometimes fun. If you are learning to program, or have done a bit of programming learn Python (or maybe Ruby). Stay away from Perl. Also don't go near PHP, please!
Subscribe to:
Posts (Atom)